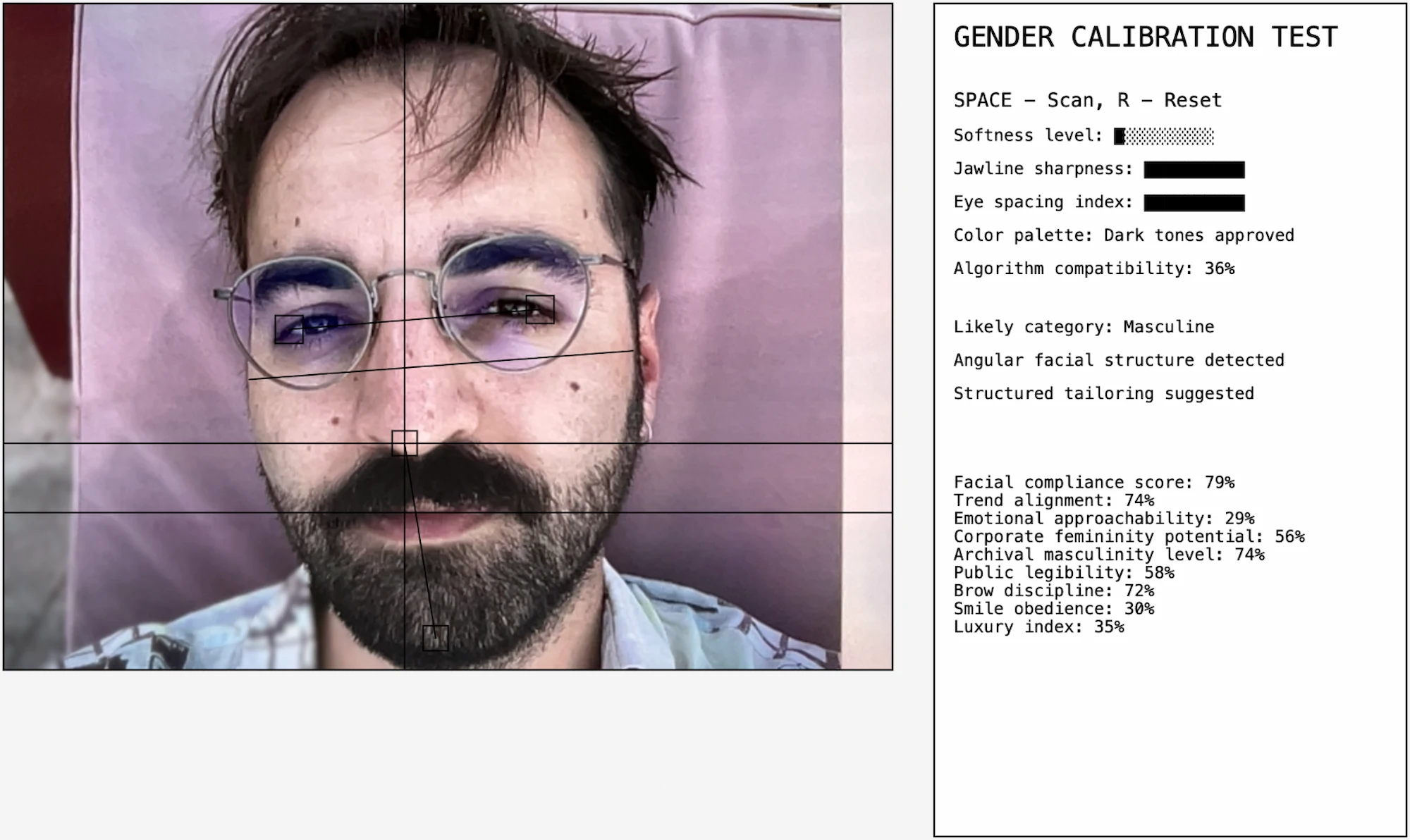
The contribution appears as an interactive interface. A webcam window is positioned on the left, showing the participant’s face with a minimal facial-tracking overlay composed of lines, grids and landmark points. On the right, a system-like panel displays real-time ‘analysis’ results.
Before interaction, all values remain empty or display ‘0%’. Participants are first asked to answer a short series of self-reflective questions through a Google Form. These questions focus on how they perceive themselves, including softness, facial structure, gender expression and style.
After submitting their answers, participants activate the scan. The interface then freezes a final ‘analysis’, allowing participants to compare their own self-description with the machine-generated classification.
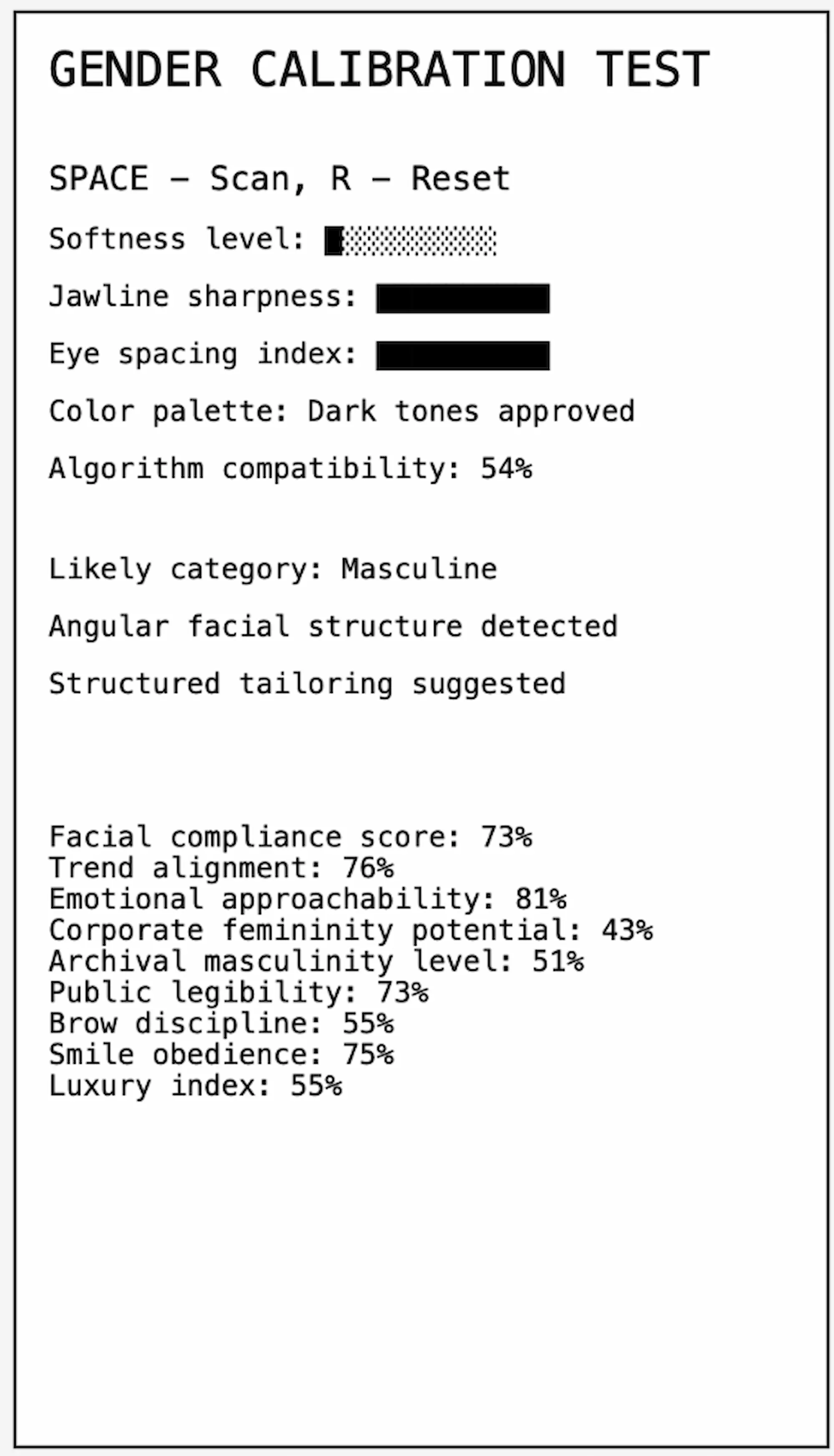
Screenshot from interactive p5.js interface.
Concept
This project explores the gap between self-perception and algorithmic classification, questioning how systems that appear technical or scientific gain authority.
The starting point comes from familiar patterns in online visual culture. Across platforms such as Instagram, TikTok and online forums, users frequently ask questions like: ‘What nose do I have?’ or ‘What face shape is this?’ These practices are closely connected to beauty standards, aesthetic trends and the increasing normalization of evaluating faces through simplified categories.
In this context, identity becomes something to be measured, labelled and optimized.
The project begins with self-description. Participants are asked to evaluate themselves before the scan takes place: how soft or sharp they believe their features are, how they perceive their gender expression and how they would classify their own appearance.
These answers are subjective, unstable and shaped by personal experience, cultural influence and social expectations.
Afterwards, the system performs its own ‘analysis’. It outputs numerical values, classifications and confident statements in a scientific tone, mimicking objectivity and precision.
However, this authority is constructed.
The system translates facial measurements into simplified classifications using arbitrary rules. For example: a higher face-height-to-jaw ratio increases ‘softness’, a wider jaw relative to face height increases ‘jawline sharpness’, eye spacing relative to face width affects ‘readability’, combinations of these values determine whether a face is categorized as ‘feminine’, ‘masculine’ or ‘unstable’.
These thresholds are intentionally exaggerated and scientifically unreliable. They imitate the logic of classification systems while exposing how unstable such systems actually are.
The project also references physiognomy — the historical belief that identity or character can be determined from facial features. Although physiognomy has been widely discredited and associated with racism, bias and discrimination, similar forms of categorization continue to appear in contemporary algorithmic systems, beauty filters and AI-generated evaluations.
The technical basis of the project builds on a face-tracking example developed by Jeff Thompson for p5.js. His code uses facial landmark detection to identify key points such as the eyes, nose and jawline. This originally functional and neutral system was adapted into a speculative interface that transforms measurements into interpretative and exaggerated conclusions about identity and appearance.
By extending a simple technical tool into a system of judgement, the project demonstrates how easily interfaces can appear trustworthy and authoritative, even when the logic behind them is unstable or constructed.
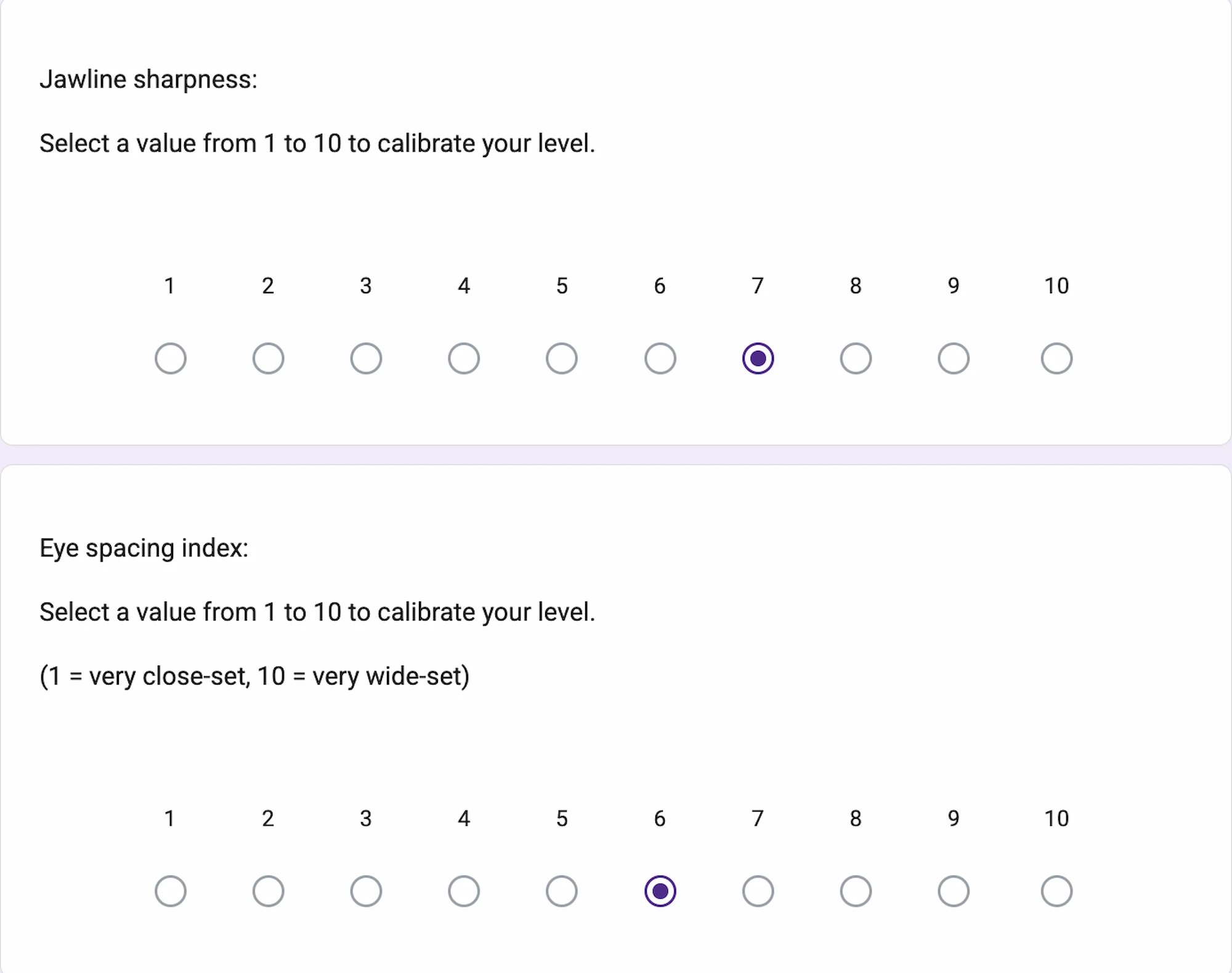
Screenshot from Google Form interface.
How it works
The system uses facial landmark detection to calculate simplified metrics such as: facial proportions (height versus width), jaw width, eye spacing, facial symmetry. These values are translated into readable outputs such as: ‘softness level’, ‘jawline sharpness’, ‘eye spacing index’, ‘algorithm compatibility’.
The interface additionally generates statements including style suggestions, behavioural warnings and target categories. Some outputs are linked to measurements while others are partially randomized, reinforcing the illusion of analytical complexity. Participants can freeze the scan at any moment by pressing the space bar. This creates a fixed ‘judgement’ that can be directly compared to their earlier self-description.
Intention
The project highlights how complex identities become reduced into simplified, data-driven categories.
By comparing self-description with machine-generated output, the work exposes: how easily algorithmic language is perceived as trustworthy, how identity becomes flattened into measurable traits, how systems reproduce norms through classification.
The generated results are often unexpected, inaccurate or contradictory. This moment of mismatch creates friction and reflection:
Why do we trust these systems?
Why do we seek validation from them?
Ultimately, the work suggests that even systems that appear objective remain shaped by cultural assumptions, aesthetic norms and historical biases — while simultaneously influencing how people understand and evaluate themselves.